Já pensou em como o Oracle calcula a estimativa de cardinalidade que uma certa query irá retornar?
Bem, vamos testar pra tentar entender. Vamos criar uma tabela e coletar as estatísticas dela:
SQL> CREATE TABLE teste_histogram(
2 id NUMBER
3* );
Table TESTE_HISTOGRAM created.
SQL> INSERT INTO teste_histogram
2 SELECT level
3 FROM dual
4 CONNECT BY LEVEL <= 10;
10 rows inserted.
SQL> INSERT INTO teste_histogram
2 SELECT 11
3 FROM dual
4 CONNECT BY LEVEL <= 500000;
500,000 rows inserted.
SQL> COMMIT;
Commit complete.
SQL> EXEC dbms_stats.GATHER_TABLE_STATS(ownname => NULL, tabname => 'TESTE_HISTOGRAM', method_opt => 'FOR ALL COLUMNS SIZE REPEAT');
PL/SQL procedure successfully completed.
SQL> SELECT tt.num_rows, ss.num_distinct
2 FROM dba_tab_col_statistics ss, dba_tables tt
3 WHERE tt.table_name = ss.table_name
4* AND tt.table_name = 'TESTE_HISTOGRAM';
NUM_ROWS NUM_DISTINCT
___________ _______________
500010 11
SQL> SELECT COUNT(*) FROM jwrep.teste_histogram WHERE id = 10;
COUNT(*)
___________
1
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS +COST'));
PLAN_TABLE_OUTPUT
________________________________________________________________________________________________________________________
SQL_ID 1sj0w7zmf9kxv, child number 0
-------------------------------------
SELECT COUNT(*) FROM jwrep.teste_histogram WHERE id = 10
Plan hash value: 3095928375
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 241 (100)| 1 |00:00:00.01 | 821 |
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 821 |
|* 2 | TABLE ACCESS STORAGE FULL| TESTE_HISTOGRAM | 1 | 45455 | 241 (2)| 1 |00:00:00.01 | 821 |
---------------------------------------------------------------------------------------------------------------------
Vamos entender um pouco o que foi feito acima e o resultado.
Primeiro criei uma tabela com apenas uma coluna do tipo number. Adicionei 10 linhas, a sequencia dos números de 1 à 10. Depois adicionei 500 mil linhas, todas com o mesmo conteúdo, o número 11.
Coletei as estatísticas e consultei elas, como número de linhas na tabela(500000) e a quantidade de valores distintos(11).
Agora, fiz um count na tabela de todos os registros que tem o número 10, no caso apenas uma linha, mas pelo plano de execução o Oracle pensou que teria 45455 linhas! Ele calculou apenas que a distribuição dos 11 valores distintos seria igual nas 500010 linhas, ou seja, 500000/11=45455.
Para corrigir esse tipo de problemas o Oracle pode criar um histogram na coluna e sendo assim calcular melhor a cardinalidade!
Vamos testar novamente!
SQL> EXEC dbms_stats.GATHER_TABLE_STATS(ownname => 'JWREP', tabname => 'TESTE_HISTOGRAM', method_opt => 'FOR ALL COLUMNS SIZE AUTO');
PL/SQL procedure successfully completed.
SQL> SELECT tt.num_rows, ss.num_distinct, ss.num_buckets, ss.histogram
2 FROM dba_tab_col_statistics ss, dba_tables tt
3 WHERE tt.table_name = ss.table_name
4* AND tt.table_name = 'TESTE_HISTOGRAM';
NUM_ROWS NUM_DISTINCT NUM_BUCKETS HISTOGRAM
___________ _______________ ______________ ____________
500010 11 11 FREQUENCY
SQL> SELECT COUNT(*) FROM jwrep.teste_histogram WHERE id = 10;
COUNT(*)
___________
1
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS +COST'));
PLAN_TABLE_OUTPUT
________________________________________________________________________________________________________________________
SQL_ID 3b6d3jrtvqm31, child number 0
-------------------------------------
SELECT COUNT(*) FROM jwrep.teste_histogram WHERE id=10
Plan hash value: 3095928375
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 241 (100)| 1 |00:00:00.01 | 821 |
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 821 |
|* 2 | TABLE ACCESS STORAGE FULL| TESTE_HISTOGRAM | 1 | 1 | 241 (2)| 1 |00:00:00.01 | 821 |
---------------------------------------------------------------------------------------------------------------------
Agora sim, o Oracle calculou corretamente a quantidade de registros, ou seja, a cardinalidade.
Isso é muito importante para o Oracle. Seja na hora de decidir por qual tabela começar a query, o tipo de join, o método de acesso da tabela e etc. É crucial para o Oracle estimar corretamente a cardinalidade para gerar o melhor plano de execução.
Então, agora podemos e devemos criar histogram em todas as colunas e em todas as tabelas? Não é bem assim.
Via de regra, não precisamos criar histograms manualmente, pois quando você referência uma coluna no where, o Oracle registra esse uso na tabela SYS.COL_USAGE$ e na próxima vez que coletar as estatísticas o Oracle irá criar o histogram automaticamente. Exemplo:
SQL> DROP TABLE teste_histogram;
Table TESTE_HISTOGRAM dropped.
SQL> CREATE TABLE teste_histogram(
2 id number
3* );
Table TESTE_HISTOGRAM created.
SQL> INSERT INTO teste_histogram
2 SELECT level
3 FROM dual
4* connect by level <= 10;
10 rows inserted.
SQL> INSERT INTO teste_histogram
2 SELECT 11
3 FROM dual
4* connect by level <= 500000;
500,000 rows inserted.
SQL> SELECT tt.num_rows, ss.num_distinct, ss.num_buckets, ss.histogram
2 FROM dba_tab_col_statistics ss, dba_tables tt
3 WHERE tt.table_name = ss.table_name
4* AND tt.table_name = 'TESTE_HISTOGRAM';
no rows selected
SQL> EXEC DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO;
PL/SQL procedure successfully completed.
SQL> select INTCOL#, EQUALITY_PREDS from SYS.COL_USAGE$ cs, dba_objects dt WHERE dt.object_id = cs.obj# AND dt.object_name = 'TESTE_HISTOGRAM';
INTCOL# EQUALITY_PREDS
---------- --------------
1 1
SQL> EXEC dbms_stats.GATHER_TABLE_STATS(ownname => 'TERCIOCOSTA', tabname => 'TESTE_HISTOGRAM', method_opt => 'FOR ALL COLUMNS SIZE AUTO');
PL/SQL procedure successfully completed.
SQL> SELECT tt.num_rows, ss.num_distinct, ss.num_buckets, ss.histogram
FROM dba_tab_col_statistics ss, dba_tables tt
WHERE tt.table_name = ss.table_name
AND tt.table_name = 'TESTE_HISTOGRAM';
NUM_ROWS NUM_DISTINCT NUM_BUCKETS HISTOGRAM
---------- ------------ ----------- ---------------
500010 11 11 FREQUENCY
Veja que o Oracle já criou um histogram automaticamente. Mas, o que é esse buckets e o que significa frenquency?
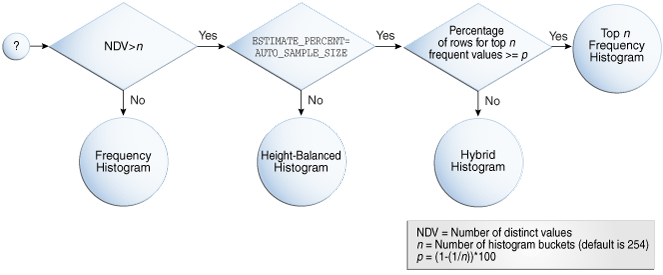
Bem, pra responder essa pergunta vamos ver os tipos de histograms que existe e como o Oracle escolhe qual criar.
Existem 4 tipos de histograms: frequency, top frequency, height-balanced, or hybrid.
E para escolher qual criar, o Oracle leva em consideração a quantidade de valores distintos(NDV), a quantidade de buckets(n, default 254) e um threshold seguindo a seguinte formula(p): (1–(1/n)) * 100.
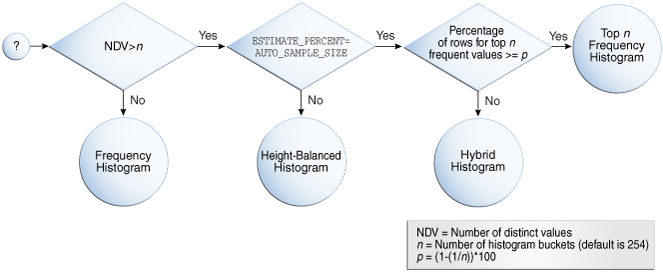
Outra coisa que pode influenciar é o parâmetro estimate_percent da package DBMS_STATS , o default é AUTO_SAMPLE_SIZE.
Agora, o bucket é onde guardamos a informação da distribuição dos valores nas colunas. Cada bucket é identificado por um endpoint number. Já o endpoint value é o valor que esta no bucket. Por exemplo, se no bucket tiver os valores 52794 e 52795, então o endpoint value é 52795.
Vamos ver alguns exemplos pra entender um pouco melhor o endpoint number e value. Vamos ver primeiro o caso de frequency histogram.
Para criar um frequency histogram, a quantidade de valores distintos deve ser menor do que o número de buckets. Vamos usar a tabela sh.countries para os testes:
SELECT country_subregion_id, count(*)
FROM sh.countries
GROUP BY country_subregion_id
ORDER BY 1;
COUNTRY_SUBREGION_ID COUNT(*)
-------------------- ----------
52792 3
52793 6
52794 2
52795 3
52796 4
52797 3
52798 3
52799 11
Como a tabela tem apenas 35 linhas e a quantidade default de buckets é 254, ao criar um histogram será criado do tipo frequency:
SQL> BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
ownname => 'SH'
, tabname => 'COUNTRIES'
, method_opt => 'FOR COLUMNS COUNTRY_SUBREGION_ID'
);
END;
/
PL/SQL procedure successfully completed.
SQL> SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
FROM USER_TAB_COL_STATISTICS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
TABLE_NAME COLUMN_NAME NUM_DISTINCT HISTOGRAM
---------- -------------------- ------------ ---------------
COUNTRIES COUNTRY_SUBREGION_ID 8 FREQUENCY
Perceba que o tipo de histogram criado foi realmente o frequency. Agora, vejamos os buckets com a seguinte query:
SQL> SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE
FROM DBA_HISTOGRAMS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
3 52792
9 52793
11 52794
14 52795
18 52796
21 52797
24 52798
35 52799
No frequency histogram, cada valor distinto tem o seu próprio bucket, esse valor sendo representado pelo endpoint value. Já o endpoint number representa a frequência do bucket atual somando com todos os anteriores. O primeiro bucket com number de 3 representa a frequência do valor 52792. Já o endpoint number 9, representa a frequência do valor 52793 mais dos buckets anteriores, que se subtrairmos dará 6. Pode comparar isso com o count distinct que foi feito na tabela. Dessa maneira, o Oracle conseguirá calcular corretamente a cardinalidade.
Existe ainda o conceito de valores populares e não populares. Valor popular é aquele aquele valor em que ocorre em mais de um bucket. Ou seja, devemos subtrair o endpoint number do bucket com o anterior, e se for maior que 1 ele será um valor popular, caso contrário será não popular.
E para calcular a cardinalidade, o Oracle segue a seguinte formulas:
cardinality of popular value =
(num of rows in table) *
(num of endpoints spanned by this value / total num of endpoints)
cardinality of nonpopular value =
(num of rows in table) * density
Densidade, density, é calculado internamente pelo Oracle, como sendo um valor entre 0 e 1.
Vamos agora para outro tipo de histogram, Top Frequency.
Como sabemos que para o top frequency precisamos ter menos buckets do que a quantidade de registros distintos, vamos coletar criar o histogram com apenas 7 buckets:
SQL> BEGIN
DBMS_STATS.GATHER_TABLE_STATS (
ownname => 'SH'
, tabname => 'COUNTRIES'
, method_opt => 'FOR COLUMNS COUNTRY_SUBREGION_ID SIZE 7'
);
END;
/
PL/SQL procedure successfully completed.
SQL> SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
FROM DBA_TAB_COL_STATISTICS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
TABLE_NAME COLUMN_NAME NUM_DISTINCT HISTOGRAM
---------- -------------------- ------------ ---------------
COUNTRIES COUNTRY_SUBREGION_ID 8 TOP-FREQUENCY
SQL> SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE
FROM DBA_HISTOGRAMS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
3 52792
9 52793
12 52795
16 52796
19 52797
22 52798
33 52799
No caso to top-frequency histogram perceba que ele ignora os casos que tem menos frequência, que no caso seria o valor 52794 que tem menos registros, 2 no caso. Top-frequency cria apenas o histogram para os top valores frequentes da tabela, ignorando os casos menores, não populares e irrelevantes na amostra.
Já o Height-Balanced Histograms é um tipo de histogram legado que era o padrão até o Oracle 11. No Height-Balanced Histogram os valores distintos são divididos entre os buckets para que cada bucket fique com aproximadamente a mesma quantidade de registros/linhas.
Veja no exemplo abaixo. Para criar um esse tipo de histogram devemos ter uma quantidade de buckets menor do que NDV. Além disso, devemos alterar o parâmetro estimate_percent para um valor que não seja o default, AUTO_SAMPLE_SIZE.
SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS (
ownname => 'SH'
, tabname => 'COUNTRIES'
, method_opt => 'FOR COLUMNS COUNTRY_SUBREGION_ID SIZE 7'
, estimate_percent => 100
);
END;
/
PL/SQL procedure successfully completed.
SQL> SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
FROM DBA_TAB_COL_STATISTICS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
TABLE_NAME COLUMN_NAME NUM_DISTINCT HISTOGRAM
---------- -------------------- ------------ ---------------
COUNTRIES COUNTRY_SUBREGION_ID 8 HEIGHT BALANCED
SQL> SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE
FROM DBA_HISTOGRAMS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE
--------------- --------------
0 52792
1 52793
2 52794
3 52796
4 52797
7 52799
6 rows selected.
Vamos entender agora um pouco sobre o high balanced. Nesse caso, como podemos ter mais de um distinct value por bucket, o optimizer pega o último(maior) registro do bucket como endpoint value. Como sabemos que a tabela tem 35 linhas, e temos 7 buckets, e como o optimizer tenta distribuir as linhas igualmente entre os buckets, o Oracle vai tentar colocar aproximadamente 5 linhas em cada bucket, e se um valor tiver que ser distribuído em mais de um bucket, o optimizer irá fazer o bucket compression, que foi o caso do valor 52799, ao invés de ter 3 buckets para os registros do valor 52799, o oracle faz o compression e o endpoint number pulou de 4 para 9. O endpoint 0 serve pra identificar o valor mínimo, e o valor máximo no caso será o último bucket.
O Oracle Optimizer fará a distribuição assim:
0 - 52792
1 - 52792 52792 52792 52793 52793
2 - 52793 52793 52793 52793 52794
3 - 52794 52795 52795 52796 52796
4 - 52796 52796 52797 52797 52797
5 - 52798 52798 52798 52799 52799
6 - 52799 52799 52799 52799 52799
7 - 52799 52799 52799 52799
Como os buckets 5, 6 e 7 tem o mesmo valor, ele faz o compression, e informa apenas o 7, pulando de bucket 4 para o 7.
Agora, por último, vejamos o Hybrid Histograms.
Nesse tipo de histogram, é combinada as características do top frequency e high balanced histograms. O Hybrid tenta corrigir um ponto fraco do high balanced histograms, quando um valor ocupa todo, ou praticamente todo, um bucket, mas não mais que um bucket, sendo assim, ele não seria considerado um valor popular, mesmo tendo uma frequência grande.
O hybrid histogram corrige isso fazendo com que o mesmo valor fique apenas em um único bucket mas adiciona mais uma informação em outra coluna, o repeat count, que é quantas vezes esse valor é repetido. Veja o exemplo:
SQL> BEGIN DBMS_STATS.GATHER_TABLE_STATS (
ownname => 'SH'
, tabname => 'COUNTRIES'
, method_opt => 'FOR COLUMNS COUNTRY_SUBREGION_ID SIZE 5'
);
END;
/
PL/SQL procedure successfully completed.
SQL> SELECT TABLE_NAME, COLUMN_NAME, NUM_DISTINCT, HISTOGRAM
FROM DBA_TAB_COL_STATISTICS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
TABLE_NAME COLUMN_NAME NUM_DISTINCT HISTOGRAM
---------- -------------------- ------------ ---------------
COUNTRIES COUNTRY_SUBREGION_ID 8 HYBRID
SQL> SELECT ENDPOINT_NUMBER, ENDPOINT_VALUE, ENDPOINT_REPEAT_COUNT
FROM DBA_HISTOGRAMS
WHERE TABLE_NAME='COUNTRIES'
AND COLUMN_NAME='COUNTRY_SUBREGION_ID';
ENDPOINT_NUMBER ENDPOINT_VALUE ENDPOINT_REPEAT_COUNT
--------------- -------------- ---------------------
3 52792 3
11 52794 2
18 52796 4
24 52798 3
35 52799 11
Os top 5 registros teria cerca de 77% da tabela, 27 linhas das total 35. Sendo assim, com 5 buckets, 77% é menor do que P((1-(1/n)*100), onde (1-(1/5))*100=80, assim é criado o histogram do tipo hybrid.
Com respeito conteúdo do bucket:
Vamos tentar balancer os registros, em 5 buckets, mas sem colocar o mesmo registro em mais de um bucket:
1 - 52792 52792 52792
2 - 52793 52793 52793 52793 52793 52793 52794 52794
3 - 52795 52795 52795 52796 52796 52796 52796
4 - 52797 52797 52797 52798 52798 52798
5 - 52799 52799 52799 52799 52799 52799 52799 52799 52799 52799 52799
Sendo assim, o endpoint repet count, é quanto se repete o endpoint value naquele bucket, e o endpoint number é a quantidade de registros acumulada, do bucket atual e dos anteriores.


Pingback: Extended Estatistics – Tércio Costa, Oracle DBA, Oracle ACE Pro, OCE MAA, OCE RAC and Grid, OCP 2019, OCE Data Guard, OCE SQL, OCP PL/SQL, OCI Architect