
Vamos agora descrever com mais detalhes algumas das funções mais usadas e que com uma maior probabilidade irá aparecer no exame.
Manipulação de Caracteres
Primeiramente vamos ver as algumas funções de Case Conversion, que poderemos modificar a aparência dos dados tanto para armazenamento como para visualização no front end e também pesquisa no banco de dados. Sabemos que os usuários são complicados, sendo assim não podemos assumir que eles armazenem os dados da maneira correta sempre. E logo depois veremos como manipular caracteres através de funções.
– Funções LOWER, UPPER E INITCAP
Todas as três funções recebem apenas um parâmetro do tipo texto e retorna todo o texto com letras maiúsculas(UPPER) ou minúsculas(LOWER) ou então apenas a primeira letra de cada palavra maiúscula e o resto minúsculo(INITCAP). Vejamos um exemplo a seguir.
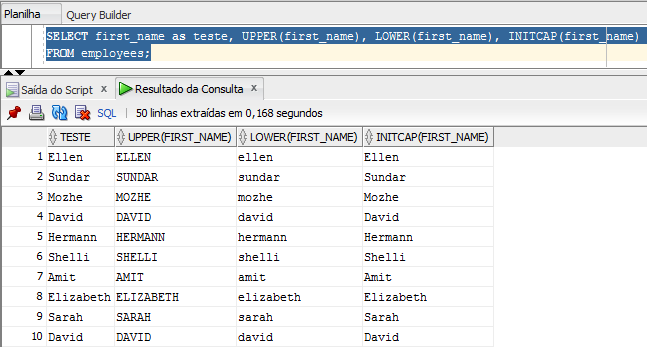
Essas funções são bastante úteis para armazenamento e apresentação dos dados. Um exemplo de como úteis podem ser essas funções é ao fazer uma pesquisa por um funcionário pelo nome, pois não sabemos como foi a entrada desses dados na hora de salvar. Será que digitaram todas minúsculas ou maiúsculas? Podemos evitar essa dor de cabeça ai pesquisar com alguma dessas funções e também padronizar a saída dos dados para ficar elegante.
CONCAT e ||
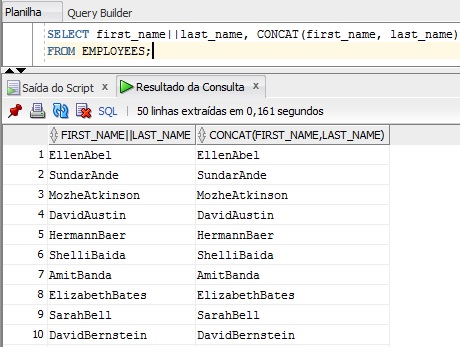
Essa é uma função que já falamos aqui anteriormente no blog. Mas vimos apenas o operador || que concatena a string anterior do operador com a posterior. A função CONCAT faz a mesma coisa, veja no exemplo a seguir.
Função LENGTH
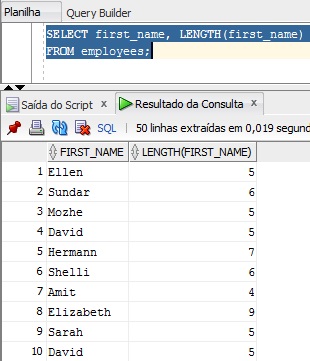
Essa função é bastante simples, na qual recebe uma string como argumento e retorna a quantidade de caracteres. Um exemplo bastante simples é mostrado na imagem a seguir.
LPAD, RPAD
Essas duas funções são bastante parecidas. Ambas as funções completam uma determinada string passada como parâmetro com um caractere que também é passada por parâmetro, mas que é opcional e caso seja emitido será espaço em branco, até ter um tamanho que também especificamos. Para entendermos melhor, vamos ver um exemplo:
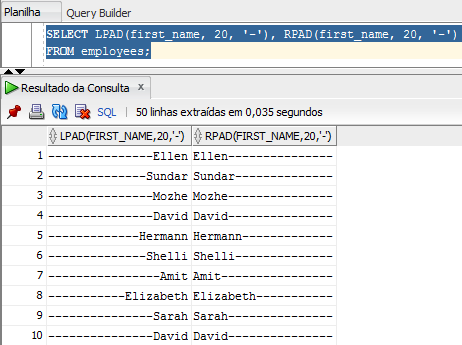
A única diferença entre as funções é que uma completa a string à direita e a outra à esquerda. Lembrando que se especificamos o tamanho da string e caso já seja menor que a string original, será retornada uma substring. Pode parecer que essa função seja um pouco inútil, mas lembre que podemos aninhar funções e teremos uma aplicação bem maior. Pense como ambas essas funções podem nos ajudar a construir um sumário ou índice de um livro.
LTRIM, RTRIM, TRIM
Ambas as funções desempenha o mesmo papel, remover um determinada string a direita da string original, a esquerda ou de ambos os lados. Bastante útil quando as vezes o usuário manda salvar algum campo com espaços no inicio, final ou ambos os lados.
A sintaxe de LTRIM e RTRIM sáo idénticas: RTRIM(s1,s2) e LTRIM(s1,s2), removendo a string s2 da string s1 no início ou no fim. O parâmetro s2 é opcional e pode ser omitido, caso seja feito assim a função irá considerar espaços em branco.
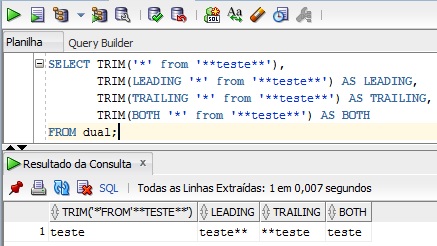
Já a sintaxe da função TRIM difere um pouco, apesar de ter um papel quase igual das funções anteriores. Com ela podemos especificar se queremos remover no início, no final ou nos dois lados. A sintaxe é a seguinte: TRIM(orientação s1 from s2). Orientação é opcional e pode ser LEADING(início), TRAILING(fim) e BOTH(início e fim), caso seja omitido será considerado BOTH. s1 será a string a ser removida de s2, também é opcional e caso seja omitido será considerado a string de espaço em branco. Agora vamos ver um exemplo.
INSTR
Essa função é usada para localizar uma string dentro da outra, retornando assim a posição de onde ela começa. Caso não encontre é retornado zero. A sintaxe é a seguinte: INSTR(s1, s2, pos, n). Onde s1 e s2 são obrigatórios e o restante é opcional, caso sejam omitidos os valores assumidos é 1. s1 é a string fonte e s2 é a string que desejamos localizar em s1. pos significa a partir de que posição da string s1 irá iniciar a pesquisar e por ultimo n, significa em quantas ocorrências é que desejamos contar, um exemplo seria retornar o resultado apenas na segunda ocorrência de s2 em s1. Caso pos seja negativo a pesquisa irá iniciar da direita para esquerda. Vejamos um exemplo:
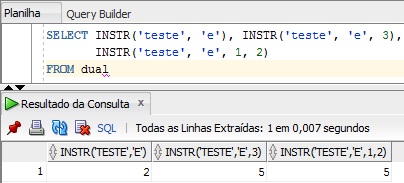
Na primeira chamada da função acima, utilizamos apenas os dois primeiros parâmetros que são opcionais e nesse caso ele localiza a primeira ocorrência da string ‘e’ na string ‘teste’ a partir do inicio da string. Já na segunda chamada, repetimos os dois primeiros parâmetros, mas colocamos o terceiro parâmetro que significa que a pesquisa deve começar a partir da posição 3 da string. E a última chamada utilizamos todos os 3 parâmetros, em que pedimos para localizar a string ‘e’ na string ‘teste’ a partir da primeira posição e retornar o resultado somente da segunda ocorrência da string.
SUBSTR
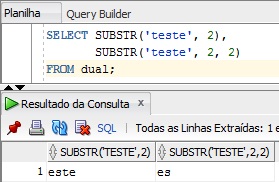
Com essa função, conseguimos retornar apenas uma porção da string do tamanho desejado e também escolhemos a posição do início da substring. Vejamos a sintaxe da função: SUBSTR(s , pos , tam). S é a string em que iremos extrair apenas uma parte. Pos é a posição da string S que irá iniciar a extração. E por último tam, que é opcional, é o tamanho da substring. Lembrando que se pos for maior que s, será retornado null. E se pos for negativo, a contagem da posição irá iniciar da direita para esquerda. Exemplo logo a seguir.
REPLACE
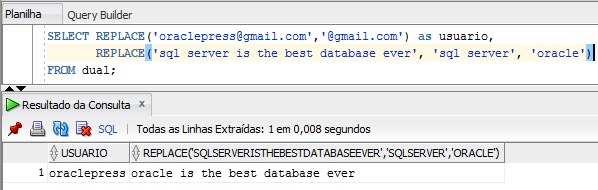
Com a ajuda dessa função, podemos substituir alguma parte da string por outra. A sintaxe é a seguinte: REPLACE( s1 , s12, s3). S1 e s2 são obrigatórios e s3 não. S1 é a string original, s2 é a string que iremos procurar em s1 e s3 é a string que iremos substituir caso encontre s2. Caso s3 seja omitido, será utilizado s3 como sendo espaço vazio, ou seja, s2 será removido de s1. Exemplo:
SOUNDEX
Esta função é única no que ela faz. Aceita apenas um parâmetro, uma string, e retorna o padrão de como soa essa palavra. Com isso podemos pesquisar palavras que tem a pronuncia bem parecida. Lembrando que o resultado é a primeira letra da string dada e mais 3 números em sequência de acordo com uma tabela.
Conseguimos analisar com esse post várias funções de manipulação de caracteres, no próximo post veremos funções matemáticas e logo depois as funções de datas. Iremos dividir em mais de um post para não ficar muito grande.

